Hasta aquí, el artículo de Tesio. Este pdf de «ayuda» es lo que he ido escribiendo para entender a mi manera esta información. Tendrá errores, seguro, así que recomiendo que cada cual se enfrente a las fuentes y cometa su propios errores. Y si alguien me corrige los míos, pues sería todo un lujo.
Los sistemas de inteligencia artificial y aprendizaje automático (AIML) operan hoy en las infraestructuras críticas, como banca, defensa y moderación de contenidos. Su funcionamiento depende de los datos y los bucles de retroalimentación continua. Esa misma arquitectura genera vulnerabilidades estructurales que pueden ser explotadas sin necesidad de acceder a los modelos, solo a los conjuntos de datos de entrenamiento.
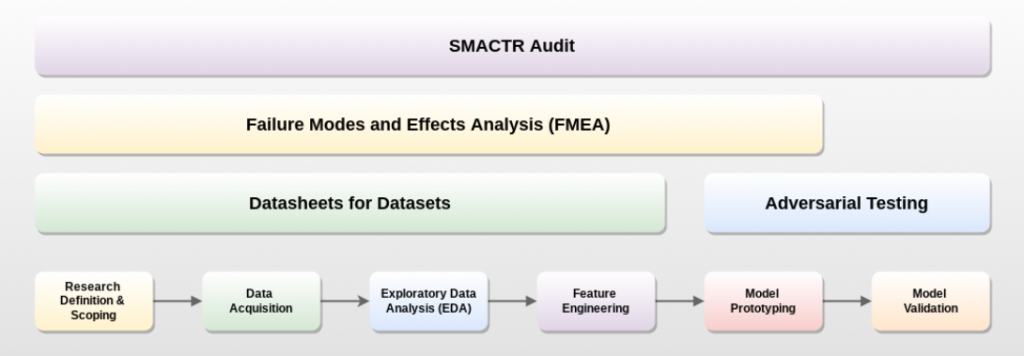
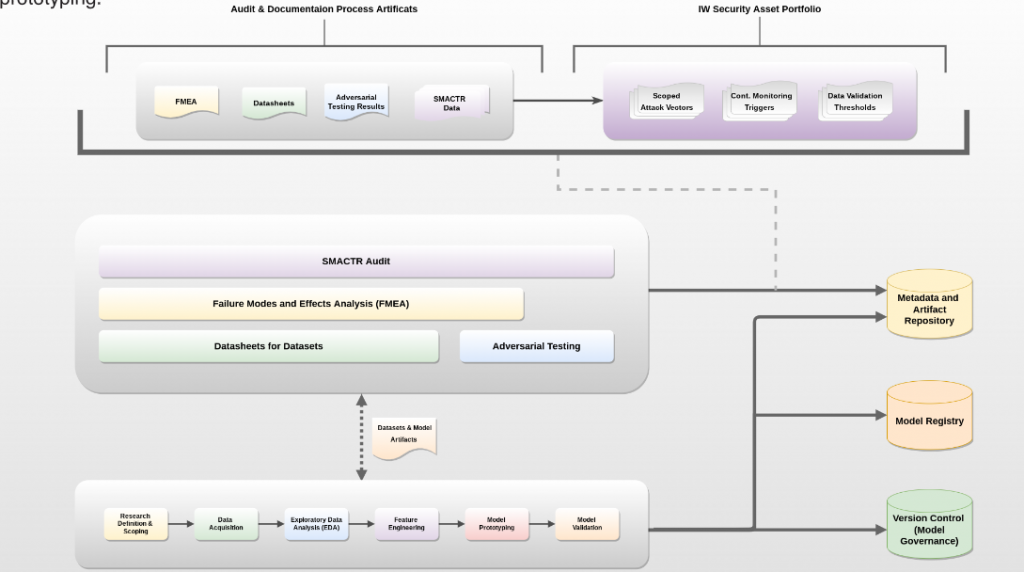
He preparado un análisis del trabajo de Susanna Cox (2022) «Securing AIML Systems in the Age of Information Warfare», donde se expone un marco de mitigación integrable en pipelines MLOps existentes. El documento identifica fallos por etapa (adquisición, entrenamiento, despliegue, retroalimentación) y propone herramientas concretas: FMEA, pruebas adversariales, datasheets, model cards, triggers, umbrales y monitorización con revisión humana solo en casos definidos.
Las imágenes que ilustran esta entrada son del artículo original.
La guerra de información no es un escenario hipotético. Existen ataques documentados de envenenamiento de datos, deriva de concepto inducida y amplificación de sesgo a través de bucles. Los marcos éticos generales han demostrado ser difíciles de operacionalizar. Shoshana nos ofrece un blueprint práctico que merece la pena estudiar.
Este texto es relevante para profesionales de AIML, equipos de seguridad, gestores de riesgos y organizaciones que desplieguen modelos en entornos donde la integridad de los datos y la resiliencia a la manipulación son requisitos operativos.
Esta es mi interpretación y puede contener errores, estudien la fuente original y cometan sus propios errores. Es como se aprende.
Esto es lo que he sacado en claro, tal vez esté equivocado, tal vez alguien que sepa más matemáticas que yo pueda corregirme. Pero espero que les resulte de utilidad para comprender los riesgos inherentes de los modelos mal llamados «IAs».
La seguridad total de un modelo de IA es inalcanzable. No es una cuestión de recursos: la geometría del espacio de entrada de alta dimensión garantiza la existencia de subespacios contiguos donde cualquier vector de perturbación induce un error de clasificación. Esto hace que la transferibilidad de ataques entre modelos sea inevitable. Las defensas actuales no eliminan este problema. Es un hecho tanto empírico como estructural, no una opinión.
La afirmación de que los sistemas de IA militares son inmunes a los ataques adversariales es una creencia falsa que contradice los fundamentos matemáticos de la disciplina. Las vulnerabilidades discutidas son estructurales y universales. El Pentágono, a través de sus propios informes oficiales (GAO 2018), ha reconocido la gravedad y el alcance sistémico de sus problemas de ciberseguridad. Los enfoques tradicionales de prueba no pueden ofrecer garantías, y la cultura del secretismo es incompatible con los únicos métodos rigurosos de cuantificación del riesgo. Por todo ello, la seguridad total es una quimera inalcanzable para los sistemas de IA, independientemente de su propósito o presupuesto.
Esta web utiliza cookies propias y de terceros para su correcto funcionamiento. Contiene enlaces a sitios web de terceros con políticas de privacidad ajenas que podrás aceptar o no cuando accedas a ellos. Al hacer clic en el botón Aceptar, acepta el uso de estas tecnologías y el procesamiento de tus datos para estos propósitos.